Rechtes Sprechzeug Über Podcasts, Plattform-Oralität und das «Intellectual Dark Web»
Drei Stunden sprach Donald Trump am 26. Oktober 2024 – und damit zwei Wochen vor der Präsidentschaftswahl – mit dem Podcaster Joe Rogan. Nachdem Trump die Wahl am 5. November gewonnen hatte, erschienen an verschiedenen Publikationsorten Stellungnahmen, die Podcasts einen erheblichen Einfluss an Trumps Erfolg zusprachen. Nicht zuletzt wurde Kamala Harris vorgeworfen, dass ihre Weigerung, ebenfalls in Joe Rogans Podcast aufzutreten, sie möglicherweise den Wahlsieg gekostet habe. Harris hatte eine Reihe von Podcastauftritten, unter anderem im populären Call her Daddy-Podcast absolviert. Der Einladung von Joe Rogan war sie aber nicht nachgekommen, da dieser eine Begrenzung des Gesprächs auf eine Stunde abgelehnt hatte. Elon Musk bezeichnete dies als Fehler: «I actually posted on X [that] nothing would do more damage to Kamala’s campaign than going on Joe Rogan, because she’d run out of non sequiturs after about 45 minutes.» Musk unterstrich demgegenüber im November 2024: «I think it made a big difference that President Trump and soon to be vice-president Vance went on lengthy podcasts.»
Inzwischen sind jenseits journalistischer Artikel eine Reihe von Beiträgen und Untersuchungen erschienen, die die unterschiedlichen Bedeutungen und Reichweiten von Podcasts in der politischen Diskussion beleuchten. Eines der am weitesten verbreiteten Artefakte dieser Debatte ist die Infografik der progressiven Watchdog Organisation Media Matters vom März 2025.
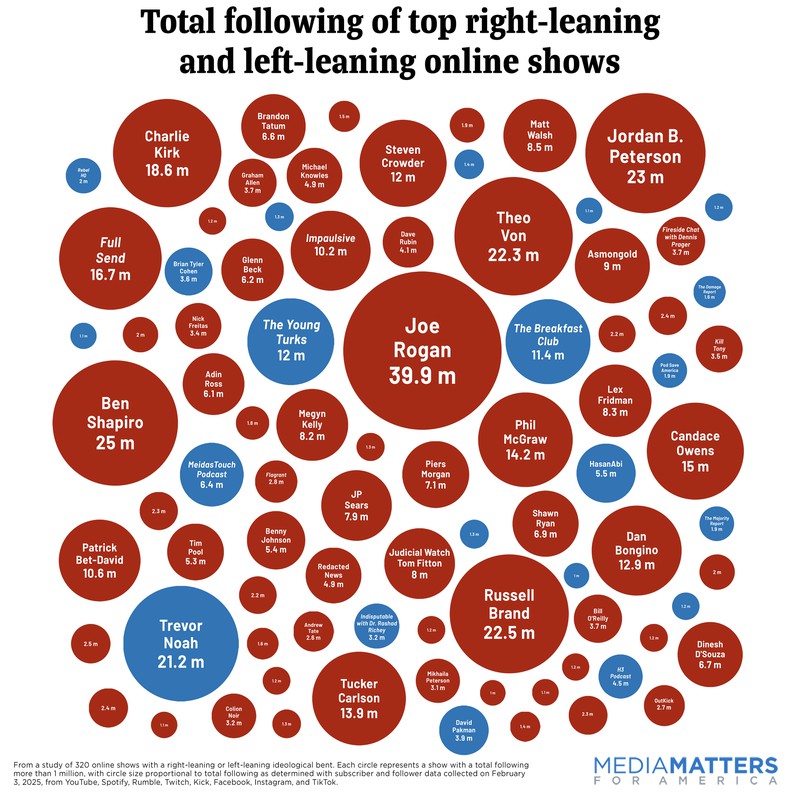
Die Grafik stellt die überwältigende Reichweite rechter Podcasts im Vergleich zu als progressiv oder links markierten Podcasts in der amerikanischen Öffentlichkeit drastisch dar. Gut 480 Millionen HörerInnen rechter Podcasts würden nur etwa 100 Millionen HörerInnen progressiver Sendungen gegenüberstehen. Die damit einhergehende Suggestion lautete, dass diese Asymmetrie ausgeglichen werden müsste, was nicht nur zukünftige PräsidentschaftskandidatInnen einschließen dürfte.
Sicher ist, dass Podcasts eine Aufwertung des Sprechens in der öffentlichen Sphäre mit sich gebracht haben, die auf momenthafte Effekte und diskursive Kraftgesten setzenden Akteuren wie Donald Trump entgegenkommt. Eine Aufwertung, die das Sprechaktmanagement, seine Tonalität und affektive Kompatibilität, in neuartige Charismaperformanzen münden lässt, die mit Begriffen der Rhetorik nur schwer zu beschreiben sind. Rechte Gefühle sind sprechendes Fühlen – und dennoch erfasst die Subsumtion dieser neuartigen und politisch so wirkmächtigen Formation des Sprechens unter Affektpolitiken nicht die gesamte Breite der zugrunde liegenden – nicht zuletzt: medientechnischen – Entwicklungen.
Podcast, das ist zunächst einmal festzuhalten, ist ein unzulänglicher Begriff für die Zirkulationsmechanismen von Sprechperformanzen, die nahtlos zwischen reinen Audiostreams im klassischen Podcast, Videostreaming, Reels auf TikTok und Instagram, aber auch in Transkriptionen von Interviews kursieren. Noch aus der Präplattformära stammend und als Begriff drei Jahre vor dem Smartphone 2004 durch den Guardian-Journalisten Ben Hammersley geprägt, sind die heute zusammenstehenden diskursiven Praktiken, technischen Affordanzen und strategischen Assemblagen verzweigter als zu diesem Zeitpunkt. Die damaligen medientechnischen Bedingungen liegen in der von Tristan Louis, einem Blogger, vorgeschlagenen und von dem Programmierer Dave Winer im Jahr 2000 erstmals realisierten Kombination aus RSS und Audiofiles.
Das Akronym RSS steht für Real Simple Syndication und zeigt die beabsichtigte Vereinfachung bei der Verbreitung von Inhalten an. Anstelle eines damals im Netz üblichen aktiven Aufsuchens einer Website, eines Blogs oder eines Audioinhalts konnten Updates nun als Push-Format automatisch an die NutzerInnen verteilt werden. Ursprünglich für die damals populären textbasierten Bloggingformate entwickelt, um deren LeserInnen automatisiert aktuelle Updates zuzustellen, erweiterte Winer RSS vor dem Hintergrund des Aufstiegs von damals «Audioblogs» genannten Formaten für Audiodateien.
Auf diese Weise auf Sendung gehend, wurden in Audioplayern die jeweils aktuellen Folgen angezeigt. Während die ContentkonsumentInnen bis auf die einmalige Subskription des RSS-Feeds keine Aktivität entfalten mussten, verblieb auf Seiten der Podcaster, Blog- und WebseitenbetreiberInnen die Notwendigkeit, den Feed mit aussagekräftigen Metadaten zu versehen. Neben dem Podcast-Titel gehörten dazu Angaben über die Sprache, Zeitstempel und die Kategorisierung des Inhalts mittels Stichworten, inklusive Hinweise auf sensitiven Content. Erweitert werden konnten diese Angaben um kurze Summaries, die in den Playern angezeigt wurden.
Sollte RSS eine Dezentralisierung von Blog- und Podcastproduktion ermöglichen, so hat sich dies inzwischen in sein Gegenteil verkehrt. Das auf RSS basierende Format ist etwa seit 2010 weitgehend durch eine Plattformisierung der Podcasts abgelöst worden – ein Prozess, der selbst wiederum gerade durch RSS begünstigt wurde. Denn: Die Indexikalisierung von Podcasts wurde durch RSS auch für die Plattformen erleichtert. Der Zugriff von Plattformen auf Audiocontent – und das bedeutet: auf gesprochene Sprache – vereinfachte sich erheblich. Die Metadaten der Podcasts flossen dabei in die Weiterverarbeitung ein, nahmen doch die Podcaster durch das Labeln ihres eigenen Contents einen Teil der Indexikalitätsarbeit für das maschinelle Lernen vorweg. Der Podcast war noch ein Download, der auf lokalen Rechnern oder MP3-Playern gespeichert werden musste und dort um stets knappen Speicherplatz mit anderen Downloads konkurrierte. Heute werden Podcasts fast ausschließlich von den Plattformen in deren Clouds gespeichert – eine Architektur, von der aus der Datentransfer zu den Smartphones via 4G und 5G Netzwerken streamförmig bedient wird. Die komprimierten und oft App-spezifisch verschlüsselten Datenströme bleiben dabei ephemer – in den Smartphones werden jeweils nur kurze Sequenzen lokal vorgehalten.
Was hier in den zwei Dekaden seit dem Aufkommen des Begriffs Podcast entstanden ist, ist ein sehr viel komplexeres und ausgreifenderes Dispositiv, in dem – um dieses vielbemühte Bonmot der Medienwissenschaften zu variieren – das Sprechzeug an den Gedanken mitarbeitet. Sprechzeug ist das heterogene Ensemble aus Smartphones, Kopfhörern, Podcasts, Online-Video-Apps und Reels, aus Mobilfunknetzwerken und den Graphennahmen der Plattformen. Deren automatisierte und KI-basierte Contentextraktion – mitsamt Automatic Speech Recognition und großen Sprachmodellen – dient der werbebasierten Feedkonstruktion und stellt den KonsumentInnen individuell personalisierte Feeds zu. Nebst den regulatorischen Bedingungen und Entscheidungen, Gesetzen und Architekturen, die diese Form von Medien mit ihren Vorschriften zu sensitivem Content, Diffamierung, (Des-)Information usf. mitprägen.
Es ist dieses durch das Smartphone und KI als zwei aufeinander aufbauende Entwicklungen entscheidend geprägte Sprechzeug-Dispositiv, das das Verhältnis zum gesprochenen Wort dramatischen Veränderungen unterwirft. Das Smartphone ist nicht nur eine allzeit verfügbare Mikrophonplattform, es ist ein entscheidendes Element in einer komplexen plattformverwiesenen Kette der Verarbeitung mündlicher Sprache, die tief in die Cloudinfrastrukturen hineinreicht und für deren Betreiber von strategischer Bedeutung ist. Auf den Smartphones selbst ist die Aufbereitung mündlicher Rede derweil bis in die Prozessorarchitekturen eingewandert, wo eigene Coprozessoren für die Filterung des Sprechens seit mehr als zehn Jahren die Norm sind. Stimme und Hintergrundgeräusche werden in Echtzeit gefiltert und getrennt, wofür inzwischen eigens trainierte KI-Modelle zum Einsatz kommen. Die zum Smartphone gehörenden Bluetoothkopfhörer sind selbst Minicomputer, die diese Funktionen sowohl an den eingebauten Mikrophonen wie an den Lautsprechern unterhalten.
Neben diesen körperbegleitenden Elementen von Smartphone, Kopfhörer und Wearable gehört in das Dispositiv des Sprechzeugs plattformseitig die große Maschinerie der Verarbeitung mündlicher Rede. Hier liegen die entscheidenden Entwicklungen vor, die die Plattformisierung von Podcasts ermöglicht haben. Ihre Grundlage ist KI – und es ist gerade dieser ökonomisch enorm erfolgreiche und wahrscheinlich monetär bedeutendste Strang der KI-Entwicklung, der weitgehend ohne öffentliche Aufmerksamkeit blieb.
Ganz anders in den Selbstdarstellungen der wichtigsten Akteure der sogenannten Künstlichen Intelligenz. So hoben die in der Presse häufig als «Godfathers of AI» bezeichneten Progammierer Yann LeCun, Geoffrey Hinton und Yoshua Bengio im Rahmen ihrer Auszeichnung mit dem als Nobel-Preis der Informatik geltenden Turing Preis hervor, dass die Spracherkennung bereits 2009 den ersten bahnbrechenden Erfolg neuronaler Netzwerke in Plattformen darstellte. Noch bevor das in den meisten Narrativierungen der gegenwärtigen KI-Epoche als disruptiv angeführte AlexNet 2012 die Mächtigkeit der Verfahren des maschinellen Lernens in der Bilderkennung demonstrierte, hatte Google Deep Learning zur Grundlage sowohl der Sprachsuche auf Android wie der automatischen Sprachverabeitung in YouTube-Produktionspipelines gemacht.
Automatic Speech Recognition (ASR) lautet die Sammelbezeichnung für maschinelle Verfahren der Spracherkennung. Ihre Leistung besteht in der Transkription gesprochener Sprache in Text für die Weiterverarbeitung in den Plattformpipelines. Spätestens seit 2009 dominiert das heute unter dem Begriff KI gefasste maschinelle Lernen ASR – und ist ein essentielles Element der Plattformökonomien.
Für Recommender Systems, die die individuellen Feeds auf den Endgeräten kuratieren, stellt ASR wichtige Funktionen bereit. In der Öffentlichkeit meist mit dem Containerbegriff «Algorithmus» belegt, handelt es sich bei Recommender Systems um sehr viel mehr als einzelne Algorithmen. Die genaue und sich zudem permanent ändernde Zusammensetzung dieser Ensembles bleibt Forschung und Öffentlichkeit verborgen. Sie sind ein Kern der Geschäftsgeheimnisse der Plattformen und enthalten neben ökonomischen Optimierungen wahrscheinlich auch in unterschiedlichen Legislaturen juristisch relevante Entscheidungen. Nicht ein Algorithmus, sondern Tausende entscheiden, welche Wege Inhalte auf Plattformen nehmen. Dazu kommen plattformspezifische Priorisierungen. Auf YouTube ist beispielsweise die Rezeptionsdauer (Watch Time) ein wichtiger Faktor, der von neuronalen Netzwerken bewertet wird. Das Alter der Inhalte ist dabei sekundär. Dagegen gewichten die Recommender Engines von Instagram oder TikTok die Neuartigkeit der Inhalte höher und beziehen soziale Signale wie Clicks, Likes und Sharing stärker in ihre Empfehlungen ein.
Sicher ist, dass ASR in diesen Ensembles eine fundamentale Bedeutung zukommt. Die Übersetzung gesprochener Sprache in maschinenlesbare Texte steht am Anfang der Pipelines. Bevor ein Podcast, Video oder Reel an die Feedkonstruktion und damit Weiterverbreitung übergeben werden kann, müssen die Inhalte auf Pornografie, Terrorismus und nicht zuletzt auf urheberrechtliche Verletzungen geprüft werden. Das Auslesen der transkribierten Texte und deren Verarbeitung in Natural Language Pipelines ist dabei eine wichtige Grundlage. Erst wenn diese Prüfung bestanden wurde, können die Inhalte den weiteren Verarbeitungsschritten zugeführt werden.
Das Verhältnis von Exploration und Exploitation, also zwischen der Exposition gegenüber neuen Inhalten und der Verwertung existierenden Contents, ist dabei eine wichtige Stellschraube bei der Feedkonstruktion. Vor allem aber ist diese Konstruktion Resultat ökonomischer Kalküle: Welche Anzeigen, welche Produkte und Produktplacements eingespielt werden, geht auf das Matching mit Keywords zurück, für die Werbekunden an den entsprechenden Schnittstellen Geld geboten haben. TikTok, YouTube und Instagram unterhalten dafür eigene Zugänge, auf denen die entsprechenden Keywords auktioniert werden. Das Matching basiert wiederum auf dem Abgleich zwischen den ASR-generierten Transkripten der Videos und den ersteigerten Keywords. Die hier etablierte Transaktionalisierung des Wortes, bei der jeder Terminus dynamisch einen ökonomischen Wert zugeschrieben bekommt, ist das wirtschaftliche Fundament der Plattformen.
Dann schließlich als Feed an Smartphones ausgespielt, ist das, was zwischen diesen körpergängigen Elementen des Sprechzeugs zirkuliert, in erheblichen Teilen entweder direkt oder indirekt Resultat der Verarbeitung mündlichen Sprechens. Der radikale Einschnitt, den dieses Ensemble ermöglicht, ist die Adressierbar- und damit Durchsuchbarkeit des gesprochenen Worts. Das Sprechzeug macht möglich, was bislang Privileg der Schrift war: das Wiederauffinden von Äußerungen.
Plattformseitig ist diese durch ASR ermöglichte Durchsuchbarkeit die Voraussetzung für die rechtskonforme Prüfung und Monetarisierung von Podcasts und Videos. Subjektseitig wird so die Auswahl von Content mittels Suchwörtern in den entsprechenden Textfeldern ermöglicht. Kulturseitig stellt sie die Grundlage für die Viralität und Memefizierung dar, die auf durch ASR generierte Addressierbarkeiten rekurrieren. Tatsächlich ist nicht Google, sondern das zu diesem Konzern gehörende YouTube die größte Suchmaschine der Welt. TikTok schließt inzwischen auf, aber auch hier greifen die Eingaben in die Suchfelder und Clicks auf Hashtags, auf die Indexikalisierung der gesprochenen Inhalte durch.
Das Sprechzeug hat so die Zirkulationsbedingungen des gesprochenen Worts verändert. Was hier entstanden ist, kann als Plattform-Oralität bezeichnet werden. Es ist eine neuartige Form der Oralität, in der sich die Beziehungen zwischen Wort und Schrift, zwischen Sprechen und Schreiben, zwischen Lesen und Hören verschieben.
Intellectual Dark Web
«Intellectual Dark Web» (IDW) ist eine inzwischen schon wieder verschattete Bezeichnung für ein loses Konglomerat von AkademikerInnen, AutorInnen und PodcasterInnen, die als intellektuelle VordenkerInnen der aktuellen reaktionären Wende gelten. Zu dieser Gruppe zählten unter anderem die niederländische Politikerin Ayaan Hirsi Ali, der amerikanische Neurowissenschaftler Eric Weinstein, die Philosophin Christina Hoff Summers und, vielleicht am bekanntesten, der kanadische Psychologe Jordan Peterson. Joe Rogan war neben Ben Shapiro dabei einer der wichtigen Podcastmultiplikatoren des IDW.
Die Spannung zwischen geschriebenem und gesprochenem Wort durchzieht die Selbstdarstellungen der einschlägigen Akteure der Alt-Right. Zum einen finden sich die Betonungen der akademischen Credentials. Und fast alle, die der Alt-Right zugerechnet wurden, hatten weiterführende Abschlüsse oder waren gar ProfessorInnen. Zum anderen ist ihnen gemeinsam, dass sie Podcasts unterhalten oder mindestens als Gäste häufig in solchen auftreten. In letzteren betonen die Alt-Right AkteurInnen ihre Differenzen mit ihren akademischen Kontexten – und beklagen Anfeindungen, denen sie ausgesetzt seien. Die für das IDW charakteristischen Debatten zu Rassentheorien, zum Geschlechterverhältnis, zu Identitätspolitik, zu Religion und zur Frage legitimer Formen von Autorität fanden dabei nicht primär in universitären Hörsälen und Buchhandlungen oder anderen modernen Dispositiven der Schriftlichkeit statt. Rezipiert wurden diese Debatten über Kopfhörer – zugestellt über Architekturen, die Feeds streamen, aber auch deren Auswahl und Gestaltung mittels Suchoptionen erlaubten.
Es ist wahrscheinlich nicht zuletzt der drohende oder tatsächliche Ausschluss aus akademischen Reputationsökonomien, der individuell den Weg in neue plattform-orale Diskursformationen eröffnet hat. Der Pariastatus und dessen Geltungsüberschüsse in rechten Milieus sind dabei hilfreich, aber es ist die Kombination aus bereits erreichter Statussicherheit, weitgehender ökonomischer Unabhängigkeit und Netzwerkkompetenz mit daraus resultierender Immunität gegen die negativen Effekte auf akademische Legitimität, die diese sich über Jahre und inzwischen Jahrzehnte erstreckenden Karrieren ermöglichten. Dazu kommt die perverse Feedbackschleife der paradoxerweise positiven Valuierung des Verhältnisses zu den Universitäten in rechten Netzwerken. Akademische Affiliationen unterstrichen nicht nur die Autorität der AkteurInnen, sondern erlaubten es ihnen, sich als Frontkämpfer im Kreuzzug für Aufklärung und Rationalität und gegen die akademischen Verirrungen, wie den ‹Wokesimus›, zu inszenieren.
Am Intellectual Dark Web zeigt sich das komplexe und parasitäre Verhältnis von Sprechen und Schreiben der Plattform-Oralität. Die maschinelle Verschriftlichung des Sprechens bleibt weitgehend unsichtbar, sichtbar dagegen ist die Bezugnahme auf die Schriftkultur in den oft Vorlesungscharakter annehmenden Einlassungen von Akteuren wie Jordan Peterson. Was hier in teilweise die Stundengrenze sprengenden Vorträgen mobilisiert wird, ist der ganze Nimbus schriftkultureller Autorität, der sich paradoxerweise an eine alphabetisierte Leserschaft richtet, die zur Hörerschaft geworden ist – und in den seltensten Fällen nachliest, was ihr das Sprechzeug zugestellt hat.
Es ließen sich eine Vielzahl analytischer Angebote aufrufen, um diese Verschiebung im Verhältnis von Oralität und Literalität zu befragen. Die Medienwissenschaften selbst tragen als eine ihrer Herkünfte die Debatten und mythopolitischen Interventionen der Oralitäts-Literalitätsdistinktion der kanadischen Schule in sich. Der eurozentristische Index und die suprematistischen Allusionen der Übervaluierung der Schrift sind in der postkolonialen und schon in der dekonstruktivistischen Debatte heftig kritisiert worden. Umso amüsanter, dass die neuerlichen Ansprüche auf den Exzeptionalismus europäischer Kultur und weißer, nicht zuletzt schriftverfugter – Homer, the Bibel, the Constitution etc. – Suprematizität im Format oraler Diskursgebung stattfindet.
Deskriptiv lässt sich jedenfalls feststellen, dass rechte und reaktionäre Strömungen die Plattform-Oralität früher und effektiver zu nutzen wussten und entlang der Evolution des Sprechzeugs gewachsen sind. Inzwischen politisch etabliert und in der größten Wirtschafts- und Militärmacht der Welt an den Schalthebeln der Macht angekommen, beginnen rechte Oralitätsliteraten die Institutionen umzubauen. Dabei erfasst die Erosionskraft dieser Formate auch die lange prestigeträchtigste Institution der Schriftkultur: die Universität. Sie hält am Schreibzeug fest, während neben ihr und teilweise in ihr das Sprechzeug ihre Fundamente längst zersetzt. Nirgends ist das sichtbarer und folgenreicher als an der Figur des Chris Rufo.
Vor zwei Jahren hatte der Gouverneur Floridas Ron De Santis Chris Rufo in das Board of Trustees des New College of Florida berufen, um dort eine Revision der Universitätscurricula zu koordinieren. In der Folge wurde unter anderem das Gender-Studies Programm des New Colleges gestrichen und Rufo erwarb sich den Ruf politischer Durchsetzungsfähigkeit. In den einschlägigen Biografien häufig als Dokumentarfilmemacher bezeichnet – eine Eigenschaft, die er mit Steve Bannon gemeinsam hat –, ist Rufo selbst ein Podcastmacher und vor allem ein häufiger Gast und Multiplikator strategischer Narrative im Podcastökosystem. Er trat unter anderem in The Daily Wire, The NatCon Podcast, The Glenn Beck Program und bei Jordan Peterson auf.
Podcasts waren die wesentlichen Schauplätze seiner seit Ende 2019 geführten Kampagne gegen die Critical Race Theory sowie der Kamapagne, die Ende 2023 zum Rücktritt der PräsidentInnen von Harvard, U-Penn und Columbia führte. In zwei ebenfalls als Podcasts durchgeführten Interviews mit der New York Times im Frühjahr diesen Jahres stellte Rufo seine Strategie für die Reform der tertiären Bildung folgendermaßen dar: «adjust the formula of finances from the federal government to the universities in a way that puts them in an existential terror and have them say, Unless we change what we’re doing, we’re not going to be able to meet our budget for the year.» Columbia, so sagt Rufo, sei der Test dieser Strategie gewesen, die nun «industrialized and applied to all of the universities as a sector» werde. Das Ziel: «leverage to extract significant reforms and to reduce the size of the sector itself.» Trumps Eskalationen gegenüber Harvard entsprechen dieser Strategie ebenso wie die Abwicklung des Bildungsministeriums. Dessen Rütteln an den Institutionen geht aber über die von ihm wenig geliebte Universität hinaus und betrifft möglicherweise grundsätzlicher die Autoritätsgehalte, Bindungskräfte und Institutionsmächtigkeit der Schriftlichkeit.
So sind die von Trump und Vance bzw. Musk begleiteten Inszenierungen im Oval Office, bei denen Cyril Ramaphosa und Volodymyr Zelenskyy vorgeführt wurden, vielleicht in dreifacher Weise als Beispiele solcher Oralitätsliterarizität zu lesen: erstens als Charismamomente, in denen die Beherrschung des Sprechakts als Ausweis von Autorität zur Ausstellung kommt; wobei zweitens der Regelbruch Wort gegen Schrift immer wieder vorführt wird; und drittens, darauf aufbauend, sofern in der Gewissheit der Viralitätsgenerativität gehandelt wird. Denn dass diese Episoden in viral verwertbare Schnipsel zerlegt werden, die den Recommender Systems der Plattformen Signale für deren Weiterverbreitung liefern, wissen die im Raum befindlichen Akteure, die auf hergebrachte Protokolle pfeifen. Auch hier ist es die automatische Transkription des gesprochenen Worts in der Pipeline, die zur Aufbereitung der Inhalte für deren Weiterverbreitung dient. Der Protokollbruch ist die Grundlage dieses Protokolls, das selbst auf Protokollen beruht, die zwar die Maschinen, nicht aber die Menschen orientieren und binden. Wie und mit welchem Zeug gegen die Dynamiken der Plattform-Oralität vorzugehen wäre, ist eine offene Frage. Dagegen anzuschreiben, wie hier im cargo-Textcontainer, ist mindestens eine Entschleunigungsübung, verfehlt aber vielleicht den Epochenmoment des Geschehens.
Christoph Engemann: Die Zukunft des Lesens ist bei Matthes & Seitz erschienen